Aleksandr Diment
Researcher
Audio Research Group
Department of Signal Processing
Tampere University of Technology
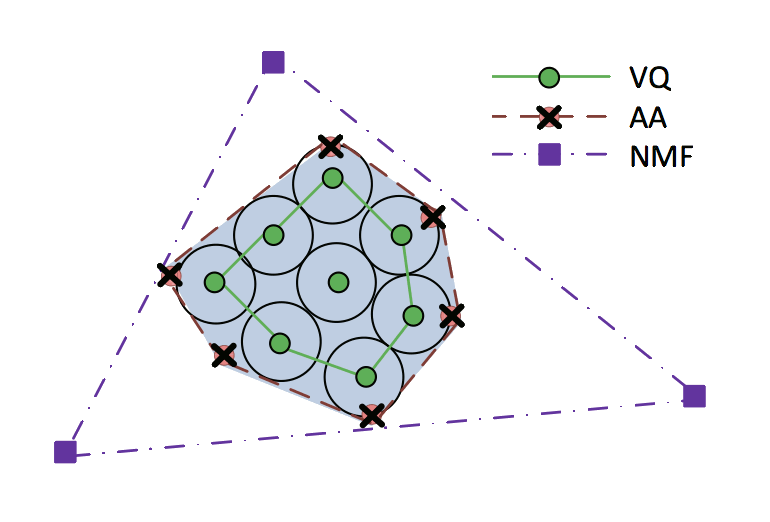
Archetypal analysis for audio dictionary learning
-
A. Diment and T. Virtanen.
Demo
| Original | ||||
|---|---|---|---|---|
| Separated | SDR, db | |||
| AA, KL | 9.54 | |||
| AA, SPAMS | 8.28 | |||
| VQ | 8.14 | |||
| Exempl | 8.33 | |||
| NMF | 3.96 |
IEEE-Copyrighted Material: Personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution to servers or lists, or to reuse any copyrighted component of this work in other works, must be obtained from the IEEE. Contact: Manager, Copyrights and Permissions / IEEE Service Center / 445 Hoes Lane / P.O. Box 1331 / Piscataway, NJ 08855-1331, USA. Telephone: +Intl. 908-562-3966.